Ops I Did It Again: From DevOps to MLOps to LLMOps
You might have heard of DevOps, MLOps or even LLMOps, but what are they really and how do they relate to one another? Each emerged to solve a distinct set of operations challenges that companies face when developing, deploying and maintaining software and models. In this blog we will look at the evolution of business needs over the past few years and how these practices evolved with them.
DevOps
Before the 2000s, software development teams and operations teams tended to work separately and isolated from one another, as described by Yevgeniy Brikman in Fundamentals of DevOps and Software Delivery: A hands-on guide to deploying and managing software in production (2025). The development teams made new features that would “work on their computer” and then pass the code on to operations. They were then in their turn responsible for deployment and maintenance of the entire software, including the latest changes. Sounds nice, right? However, in practice this would often lead to frustration and miscommunication between both teams. Development teams would hand over code that caused failures with operations teams, making them reluctant to move changes to production environments without thorough testing, slowing down the cycle of feature releases. Whenever issues would occur with the software, it was also very hard to pinpoint whether that was due to code or due to operational setup, making debugging very difficult.
As software solutions become more and more complex and bigger, the need for a more integrated collaboration between both teams arose. DevOps is a way of working where software development and operations teams work closely together, instead of functioning as separate teams. The goal is to enable a faster and more reliable product by collaborating, integrating and automating the entire process from code to production as much as possible.
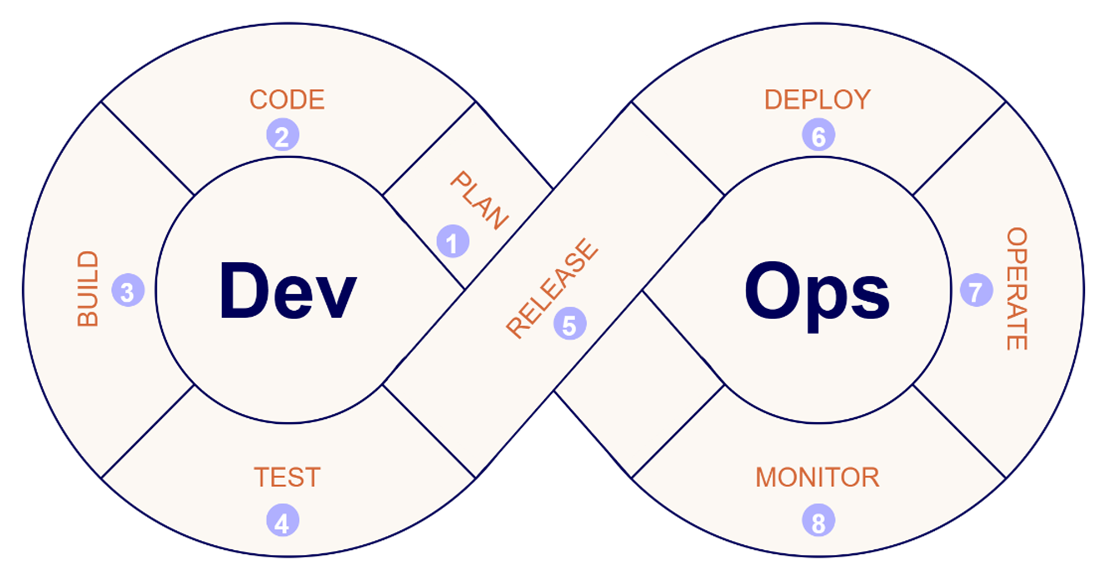
DevOps is thus not a technology but a set of practices used to automate and integrate development and operations. Each practice then has its own popular choices of technologies to implement. Practically, we say DevOps consist of roughly 8 stages, that it continuously loops through:
Plan: New features, changes or fixes that need to be taken up by the development team are defined and planned in a timeline. Some popular tools to accomplish this are Jira, Trello or Azure DevOps boards.Code: The developers make the code changes previously defined and planned in their preferred IDE and make sure to save version history using Git.Build: The adapted code is compiled to make it executable and packaged with its necessary dependencies for deployment to the target environment. This is were technologies such as Docker, Maven or npm come in.Test: This one speaks for itself, the packaged code it tested to make sure that it runs, doesn't cause any failures and meets the quality standards. Every developer’s favourite part of coding.Release: After making sure the changes are up to standard, the packaged code is formally prepped for deployment. This includes proper versioning, approval flows, generating release notes etc.Deploy: The released code changes are rolled out to the target environment, replacing the currently running version. This could impact both the infrastructure (e.g. using Terraform or bicep) and the software version.Operate: The software is managed and ran in production. Tools such as Kubernetes can help you scale this efficiently in cloud environments like Azure.Monitor: While the software is running track its performance, errors or other metrics to detect points of improvement or future issues early on. These can then be logged on your development planning board to be taken up at the right time.
Steps 3&4 (Build and Test) are also referred to as Continuous Integration or CI. They concern themselves with ensuring that problems with code changes are detected early and the code base remains in a healthy state. Steps 5&6 (Release and Deploy) are referred to as Continuous Deployment or CD. It focuses on the automated preparation and delivery of “good” software changes to production environments. There are a number of technologies such as Azure CI/CD, GitLab CI/CD or Jenkins that can cover all of these four stages in the process and help you automate each step.
DevOps is not only a set of practices, steps and their respective technologies to automate and integrate software development and IT operations, it is also important to note that it requires a cultural shift to be successful in delivering better software and faster.
MLOps
While DevOps brought development and operations together for software, a new challenge arose with the increased popularity of AI and machine learning around the mid‑2010s, as described by Mark Treveil and the Dataiku team in Introducing MLOps: How to Scale Machine Learning in the Enterprise. Unlike traditional software, machine learning models aren’t “just code”. Their quality and performance greatly depends on the data they were trained on and the data that it being fed into them on the regular. This introduces new complexity, that isn’t quite covered by the DevOps practices that we discussed before: models can degrade over time, data can change, and results are often probabilistic rather than deterministic.
Before MLOps, data scientists would experiment with models in isolation, train them on local machines, and then hand them over for deployment. Often, this would fail because the operational environment didn’t match the training setup, or the data pipelines weren’t robust. Just like pre-DevOps, this disconnect slowed down model deployment and made debugging difficult.
MLOps is the practice of applying DevOps principles to machine learning, integrating data, model, and code management with operations. Its goal is to make the entire process from data collection to model deployment faster, more reliable, and reproducible.
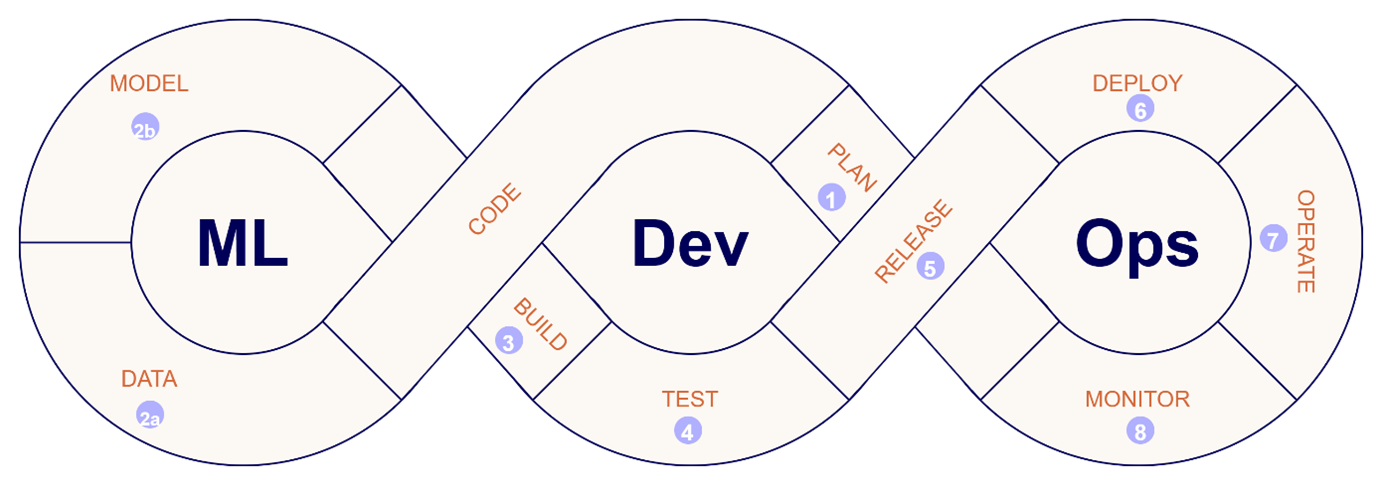
Practically, we start from the same 8 stages as we’ve seen in DevOps, using the same technologies, but we extend the coding stage with an extra data and model loop. While writing the code (previously described as stage 2 in DevOps), you get two additional tasks:
2a. Data: Before you can start with ML modelling, you need concern yourself with the collection, cleaning, processing and versioning your data, using an ETL-tool or choice such as ADF, dbt, scheduled spark scripts etc.
2b. Model: Once you have the necessary data you can start to experiment and train your models on your data, using TensorFlow, scikit-learn or other frameworks. Before moving to the next stage, you will need to test their performance on unseen data, evaluate their performance, robustness and potential biases.
Just as with DevOps, MLOps requires both cultural and technical alignment. Development, data science, and operations teams must collaborate closely to ensure that models are not only accurate but also reliable and maintainable in production.
LLMOps
The last few years you have not been able to do almost anything anymore without the involvement of Large Language Models (LLMs) such as GPT or LLaMA. Strictly speaking, LLMs are a specific kind of Machine Learning models, but we see they have their own operational needs that go beyond the standard MLOps as discussed before. LLMOps isn’t a replacement of MLOps, but rather a specialization.
Unlike standard ML models, LLMs are enormous, probabilistic, and often accessed via APIs rather than trained, packaged and deployed directly. This shifts the operational problem: instead of orchestrating training pipelines, feature stores, and GPU deployments, the focus moves to prompt engineering, retrieval pipelines, system configurations, safety layers, and integrations with external model providers. Prompt engineering in particular becomes a central discipline, as the prompts themselves determine the model’s behaviour and are effectively treated as versioned, testable artifacts, a point emphasized by Abi Aryan in LLMOps: Managing Large Language Models in Production.
At the same time, grounding LLMs in external knowledge (often through RAG architectures) is critical for accuracy and trustworthiness of your results. This introduces new challenges: documents must be properly chunked, vectorized, and indexed, search performance and latency must be optimized, and relevance of retrieved information must be continuously evaluated and trigger document updates when needed.
As LLMOps is an extension of MLOps, many of its principles still apply, think version control, monitoring, governance, data quality, and evaluation, but the way they look in practice differs. In LLMOps, you version prompts instead of model checkpoints, monitor token usage and response quality rather than model drift, and refine knowledge through retrieval rather than retraining. Safety and policy enforcement are more prominent concerns because LLMs can generate unexpected or undesirable outputs even when the underlying model is stable. And because you don’t own the model weights, you also inherit a new layer of vendor lifecycle management: updates, deprecations, API changes, and fallback strategies become part of everyday operations.
You can still think of LLMOps as following the same stages we discussed in MLOps, but with a shift in focus. Instead of training and deploying models, the “model” stage now revolves around API calls, prompt engineering, and experimenting with different (versions of) LLMs. Similarly, when we talk about data, we are no longer focused on training datasets, but on knowledge bases and retrieval systems that ground the LLM, helping to reduce hallucinations and improve the relevance of its responses.
How These Practices Fit Into an Azure & Databricks Ecosystem
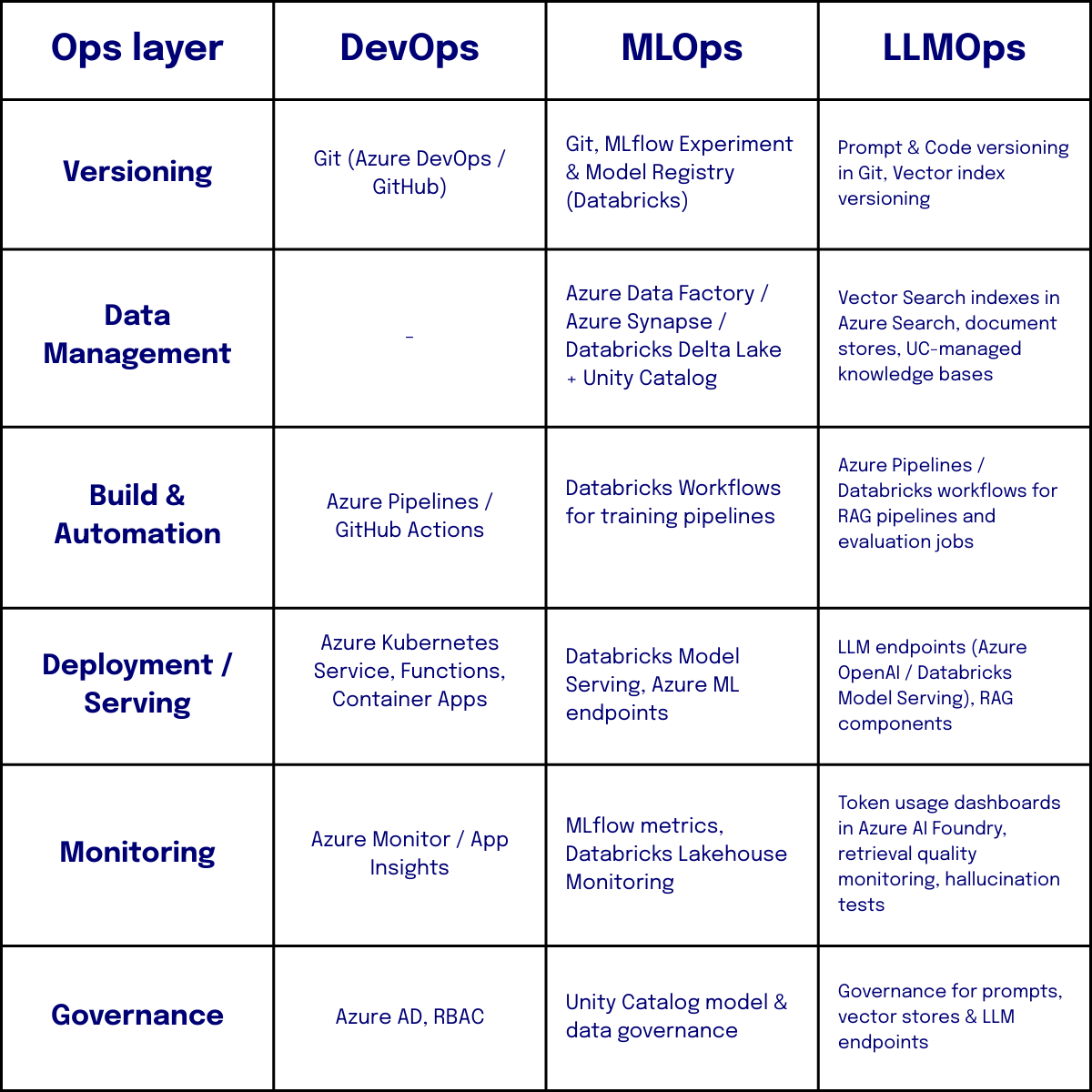
While DevOps, MLOps and LLMOps can be implemented with many different technologies, in most of our projects we see these practices come together naturally in the Azure cloud and Databricks platform. The table below shows how the concepts we discussed map to commonly used components in a modern Azure-centric data stack:
What you should remember
As we’ve seen, DevOps, MLOps, and LLMOps each evolved to address the operational challenges posed by increasingly complex software and AI systems. What started as a need to better coordinate development and operations has grown into specialized practices that handle data, models, and now intelligent language systems. While the tools and techniques differ, the underlying goal remains the same: to enable faster, more reliable, and maintainable delivery of value. Understanding these practices and their evolution not only helps teams work more effectively today but also prepares them for the next wave of innovation in software and AI operations.
The fields of DevOps, MLOps, and LLMOps are continuously evolving, and staying ahead requires both expertise and strategy. If you want to understand what these operational paradigms mean for your organization and how to implement them effectively, contact Plainsight today.
Ready to get started?
Consultation with our team at Plainsight to discuss how we can help you design, test, and scale your own IT solutions.