
Implementing Data Mesh with dbt: From principles to Practice
introduction
Most traditional organizations rely on a centralized data team to own, build, and maintain everything data related. This team supports every business domain and every team that collects or consumes data across the company. As data becomes more deeply embedded in day to day operations, the number of requests inevitably grows, along with the pressure on this central team.
Many of these requests are not complex. Teams want to explore data, compare different time periods, adjust a definition, or quickly test an idea. Yet even these small and often one off requests end up in the same queue as larger initiatives. The result is a growing bottleneck. The data team becomes overloaded, lead times increase, and frustration builds on both sides.
This is the problem Data Mesh aims to address. By shifting from centralized ownership to a decentralized model built around domain owned data products, Data Mesh promises a way for data platforms to scale with the pace of the business. However, while the concept is compelling, many organizations struggle to move from Data Mesh theory to something that actually works in practice.
This is where dbt comes in. Designed for modular and version controlled data transformations, dbt fits naturally into a Data Mesh architecture. At the same time, it is not a silver bullet. A successful implementation still requires additional organizational, technical, and governance considerations.
In this blog post, we will explore what Data Mesh really is, how dbt can support its implementation, where additional work is needed, and how you can start applying these ideas in a practical way.
What is Data mesh?
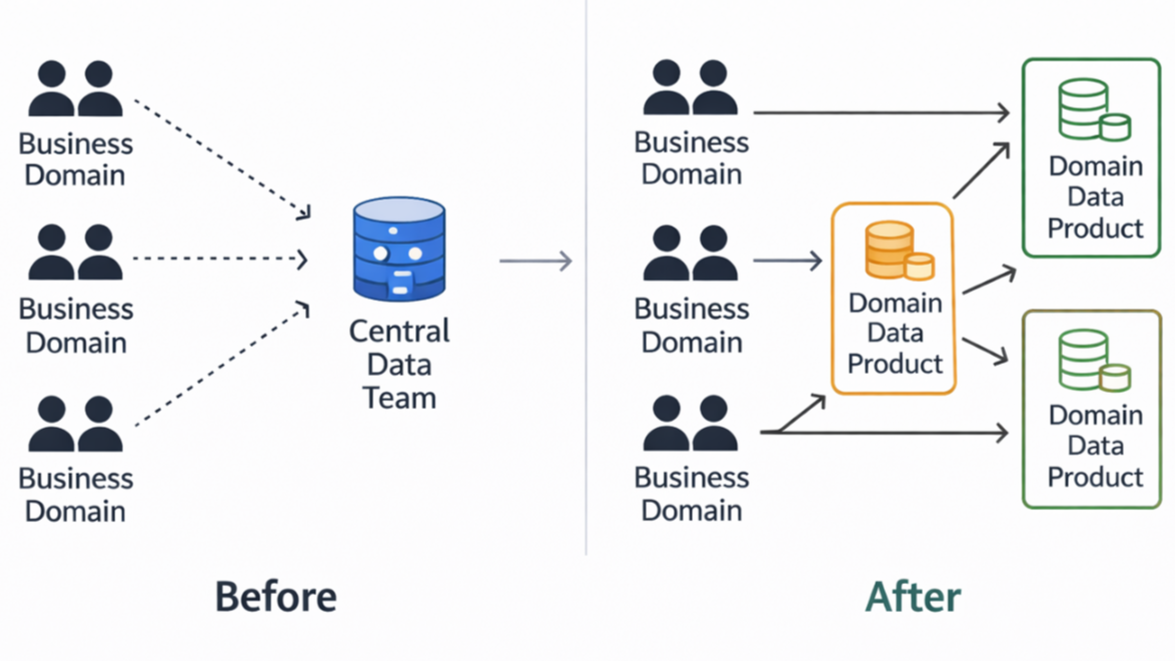
Data Mesh is a decentralized data-architecture that treats data as a product. Instead of relying on one single centralized data team, each domain-specific team owns and manages its own data. This approach improves autonomy, accelerates delivery and allows larger organisations to scale without creating bottlenecks.
Data Mesh also addresses the challenge of using data across domains. For example, building a customer 360 view requires combining data from multiple domains. Data Mesh provides a clear, governed process for sharing data products, avoiding ad hoc exports that quickly become outdated.
The term Data Mesh was coined by Zhamak Dehghani and further explained in her book “Data Mesh: Delivering Data-Driven Value at Scale”. She identifies four core principles that form the foundation of Data Mesh:
Domain-Oriented Ownership
Each domain-specific data team is responsible for the data they create and, if shared, for making it available as a data product to other domains. The teams ensure the data is accurate, up to date, and properly documented. They also manage governance, including access controls, lineage tracking, anonymization, and security.Data as a Product
Each domain treats their data as a product with data quality checks, discoverability, SLAs etc. It is professionally maintained, documented and reliably offered for consumption (also in other domains if granted access).Self-Servicing Data Platform
A shared infrastructure enables teams to build and share data products independently.Federated Governance
Central standards and guidelines are combined with more local/low-level autonomy for further governance and compliance.
To make this a bit more tangible, consider a marketing team that wants to track customer engagement. They could create a customer engagement data product that combines their own campaign performance data with customer transaction data from the sales domain. To access the transaction data, the marketing team requests permission to use the transaction data product owned by the sales team. The sales team remains responsible for maintaining their product, ensuring it is accurate, up to date, and that the marketing team only sees the data they are authorized to use.
Disclaimer: A traditional centralized architecture can still make sense for some organizations, depending on factors such as the individual domains’ data literacy, the need for fast, coordinated insights and the scale of operations. Even in a Data Mesh, it is common to maintain a central data team to manage shared infrastructure, CI/CD pipelines, reusable macros, or organization-wide definitions and standards.
How does dbt support (or limit) each principle?
Now that we understand the concept of Data Mesh, the next challenge is putting its principles into practice to fully realize its benefits. There are a lot of different tools available that can help you technically implement Data Mesh, but here we will focus on dbt and why it is such a good fit for organisations.
dbt (or Data Build Tool) is an open-source framework that allows developers to transform raw data into reliable, well-documented datasets. It is based on SQL with additional flexibility through dbt-native macros, which are essentially jinja templates that simplify complex transformations. dbt’s built-in testing, documentation and lineage tracking also make it very easy for developers to ensure data quality, track lineage and understand their datasets and maintain consistency across the organisation.
While dbt can provide the technical framework for building, testing and documenting data products in a decentralized way, the success of Data Mesh goes beyond strictly technical implementations. Organisational design, clear domain ownership, collaboration and mostly a culture that encourages domains to take accountability and clearly communicate are what makes Data Mesh implementations succeed in practice. Think of it as dbt providing the teams with structure to implement the technical side, but culture filling in the gaps.

Building blocks of a dbt-enabled Data Mesh
Let’s look at this a bit more in practice with an example. Imagine you have a company Narrowlook that implements a Data Mesh architecture (and culture). It has a number of domains, among which are Marketing, Sales and Customer Support. As we assume with a Data Mesh implementation, each domain is responsible for its own data products. The Sales team maintains a transaction data product, while the Marketing team builds a customer engagement data product that combines its own campaign data product with Sales’ transaction data product.
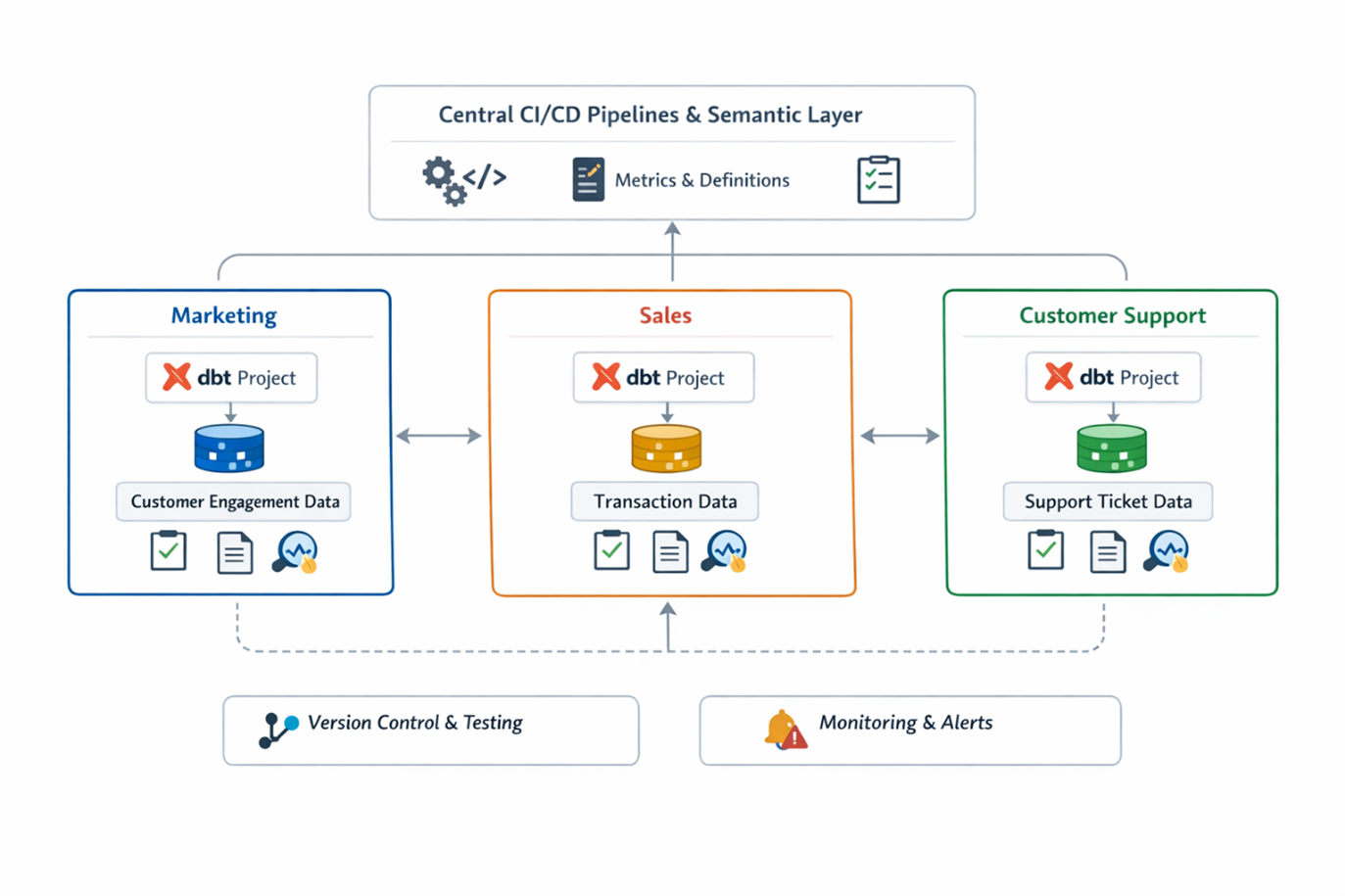
The key building blocks of this setup are:
Domain-Aligned Project Structure: Each team (Marketing, Sales, Customer Support) manages its own dbt project repository, which is git-based to ensure version control, and deploys transformations independently.
Collaboration and Transparency: Teams can explore and consume each other’s data products confidently, backed by clear documentation. They can also reuse defined metrics or macros allowing consistent calculations across domains.
Data Quality and Testing: Shared testing frameworks, including built-in dbt tests and custom macros, together with documentation and lineage tracking enforce consistency and quality across domains, while ensuring each data product is reliable and understandable.
Central CI/CD with Local Autonomy: Shared pipelines enforce quality while allowing domains to deploy independently.
Governance through Conventions: Naming standards, code reviews, documentation, and automated SQL linting with tools like SQLFluff replace central bottlenecks with clear, repeatable rules. This ensures consistent SQL style and quality across domains without slowing teams down.
Conclusion
Data Mesh addresses a growing challenge in modern data organizations: centralized data teams cannot scale with the pace of the business. By shifting ownership to domains and treating data as a product, organizations can improve autonomy, speed, and accountability.
dbt plays an important role in making these ideas actionable. It is not a Data Mesh solution on its own, but a powerful enabler of mesh practices when paired with the right organizational maturity. dbt provides the technical scaffolding for building, testing, documenting, and sharing data products, while real success depends on how teams design for data ownership, trust, and discoverability.
The most effective Data Mesh implementations look beyond tooling. They focus on clear ownership, shared conventions, and a culture where teams take responsibility for the data they produce and share.
Call to action
If you are thinking about implementing Data Mesh architecture, working with dbt or trying to move from theory to practice, you do not have to figure it out alone. At Plainsight, we help organizations design and implement pragmatic data platforms that balance autonomy with governance.
Whether you are just getting started or looking to mature an existing setup, feel free to reach out to us for a conversation. We are happy to explore how Data Mesh and dbt can work in your specific context.
